论文成果
实验室发表的学术论文列表(按年份倒序)
2025
- MIA
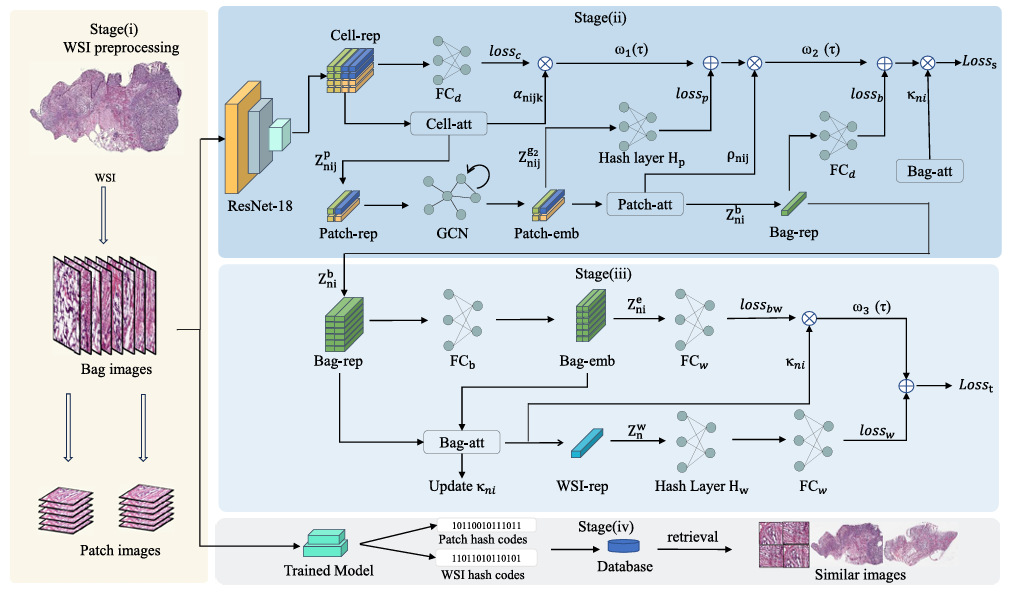 Dynamic graph based weakly supervised deep hashing for whole slide image classification and retrievalHaochen Jin, Junyi Shen, Lei Cui, and 3 more authorsMedical Image Analysis, 2025中科院JCR一区
Dynamic graph based weakly supervised deep hashing for whole slide image classification and retrievalHaochen Jin, Junyi Shen, Lei Cui, and 3 more authorsMedical Image Analysis, 2025中科院JCR一区Recently, a multi-scale representation attention based deep multiple instance learning method has proposed to directly extract patch-level image features from gigapixel whole slide images (WSIs), and achieved promising performance on multiple popular WSI datasets. However, it still has two major limitations: (i) without considering the relations among patches, thereby possibly restricting the model performance; (ii) unable to handle retrieval tasks, which is very important in clinic diagnosis. To overcome these limitations, in this paper, we propose a novel end-to-end MIL-based deep hashing framework, which is composed of a multi-scale representation attention based deep network as the backbone, patch-based dynamic graphs and hashing encoding layers, to simultaneously handle classification and retrieval tasks. Specifically, the multi-scale representation attention based deep network is to directly extract patch-level features from WSIs with mining the significant information at cell-, patch- and bag-level features. Additionally, we design a novel patch-based dynamic graph construction method to learn the relations among patches within each bag. Moreover, the hashing encoding layers are to encode patch- and WSI-level features into binary codes for patch- and WSI-level image retrieval. Extensive experiments on multiple popular datasets demonstrate that the proposed framework outperforms recent state-of-the-art ones on both classification and retrieval tasks. All source codes are available athttps://github.com/hcjin0816/DG_WSDH.
@article{jin2025dynamic, author = {Jin, Haochen and Shen, Junyi and Cui, Lei and Shi, Xiaoshuang and Li, Kang and Zhu, Xiaofeng}, journal = {Medical Image Analysis}, note = {中科院JCR一区}, pages = {103468}, title = {Dynamic graph based weakly supervised deep hashing for whole slide image classification and retrieval}, year = {2025}, } - ACL
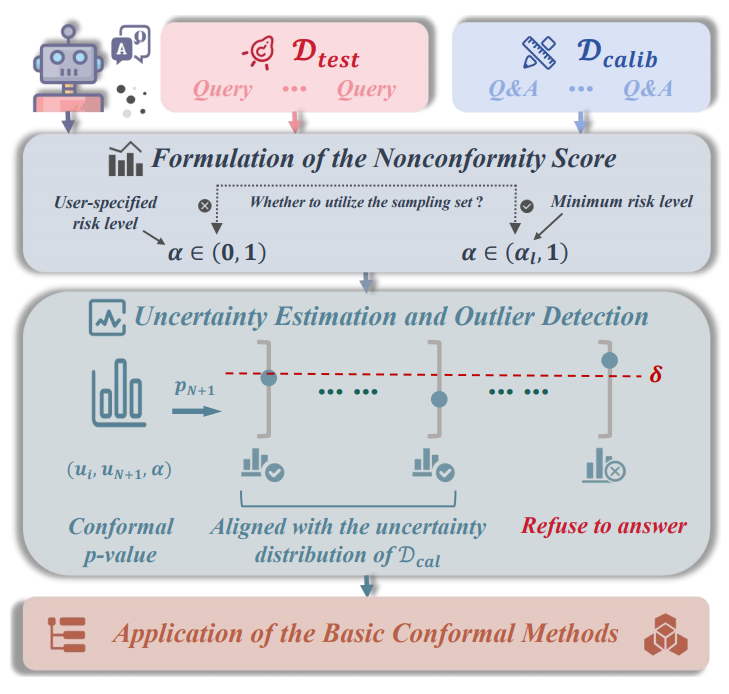 SConU: Selective Conformal Uncertainty in Large Language ModelsZhiyuan Wang, Qingni Wang, Yue Zhang, and 4 more authorsIn The Annual Meeting of the Association for Computational Linguistics (ACL), 2025CCF-A
SConU: Selective Conformal Uncertainty in Large Language ModelsZhiyuan Wang, Qingni Wang, Yue Zhang, and 4 more authorsIn The Annual Meeting of the Association for Computational Linguistics (ACL), 2025CCF-AAs large language models are increasingly utilized in real-world applications, guarantees of task-specific metrics are essential for their reliable deployment. Previous studies have introduced various criteria of conformal uncertainty grounded in split conformal prediction, which offer user-specified correctness coverage. However, existing frameworks often fail to identify uncertainty data outliers that violate the exchangeability assumption, leading to unbounded miscoverage rates and unactionable prediction sets. In this paper, we propose a novel approach termed Selective Conformal Uncertainty (SConU), which, for the first time, implements significance tests, by developing two conformal p-values that are instrumental in determining whether a given sample deviates from the uncertainty distribution of the calibration set at a specific manageable risk level. Our approach not only facilitates rigorous management of miscoverage rates across both single-domain and interdisciplinary contexts, but also enhances the efficiency of predictions. Furthermore, we comprehensively analyze the components of the conformal procedures, aiming to approximate conditional coverage, particularly in high-stakes question-answering tasks.
@inproceedings{wang2025sconu, author = {Wang, Zhiyuan and Wang, Qingni and Zhang, Yue and Chen, Tianlong and Zhu, Xiaofeng and Shi, Xiaoshuang and Xu, Kaidi}, booktitle = {The Annual Meeting of the Association for Computational Linguistics (ACL)}, note = {CCF-A}, title = {SConU: Selective Conformal Uncertainty in Large Language Models}, year = {2025} } - EAAI
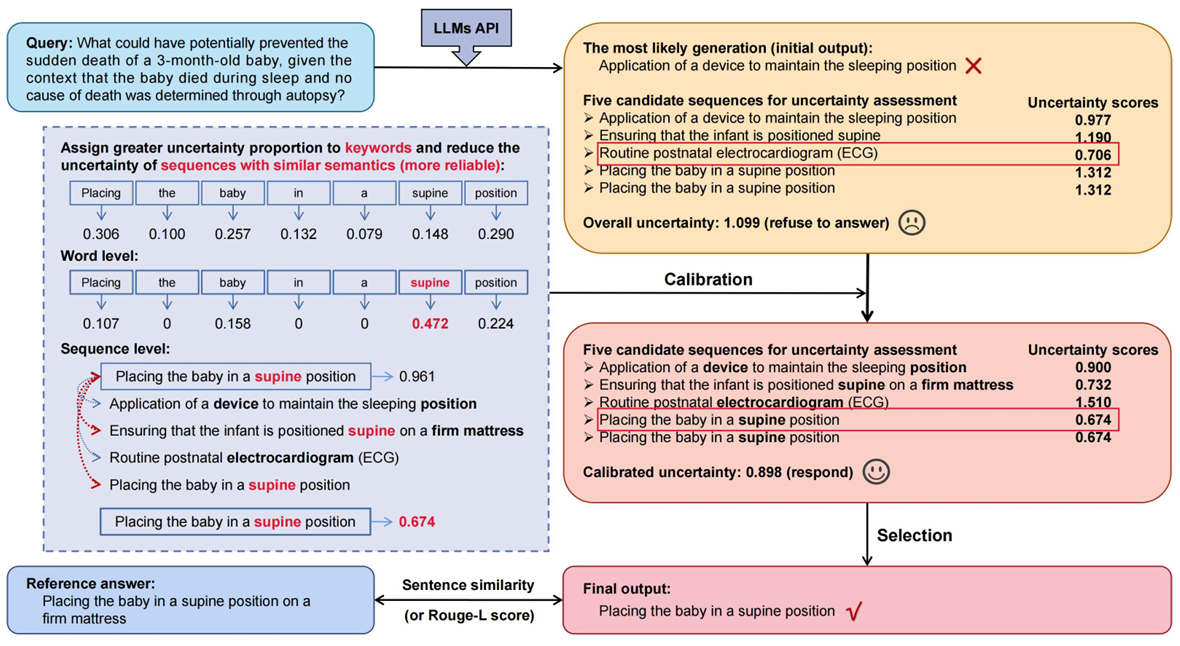 Word-sequence entropy: Towards uncertainty estimation in free-form medical question answering applications and beyondZhiyuan Wang, Jinhao Duan, Chenxi Yuan, and 6 more authorsEngineering Applications of Artificial Intelligence, 2025中科院JCR一区
Word-sequence entropy: Towards uncertainty estimation in free-form medical question answering applications and beyondZhiyuan Wang, Jinhao Duan, Chenxi Yuan, and 6 more authorsEngineering Applications of Artificial Intelligence, 2025中科院JCR一区Uncertainty estimation is crucial for the reliability of safety-critical human and artificial intelligence (AI) interaction systems, particularly in the domain of healthcare engineering. However, a robust and general uncertainty measure for free-form answers has not been well-established in open-ended medical question-answering (QA) tasks, where generative inequality introduces a large number of irrelevant words and sequences within the generated set for uncertainty quantification (UQ), which can lead to biases. This paper introduces Word-Sequence Entropy (WSE), a method that calibrates uncertainty at both the word and sequence levels, considering semantic relevance. WSE quantifies uncertainty in a way that is more closely aligned with the reliability of LLMs during uncertainty quantification (UQ). We compare WSE with six baseline methods on five free-form medical QA datasets, utilizing seven popular large language models (LLMs). Experimental results demonstrate that WSE exhibits superior performance in UQ under two standard criteria for correctness evaluation. Additionally, in terms of real-world medical QA applications, the performance of LLMs is significantly enhanced (e.g., a 6.36% improvement in model accuracy on the COVID-QA dataset) by employing responses with lower uncertainty that are identified by WSE as final answers, without any additional task-specific fine-tuning or architectural modifications.
@article{wang2025word, author = {Wang, Zhiyuan and Duan, Jinhao and Yuan, Chenxi and Chen, Qingyu and Chen, Tianlong and Zhang, Yue and Wang, Ren and Shi, Xiaoshuang and Xu, Kaidi}, journal = {Engineering Applications of Artificial Intelligence}, note = {中科院JCR一区}, pages = {109553}, title = {Word-sequence entropy: Towards uncertainty estimation in free-form medical question answering applications and beyond}, volume = {139}, year = {2025}, } - InfoFusion
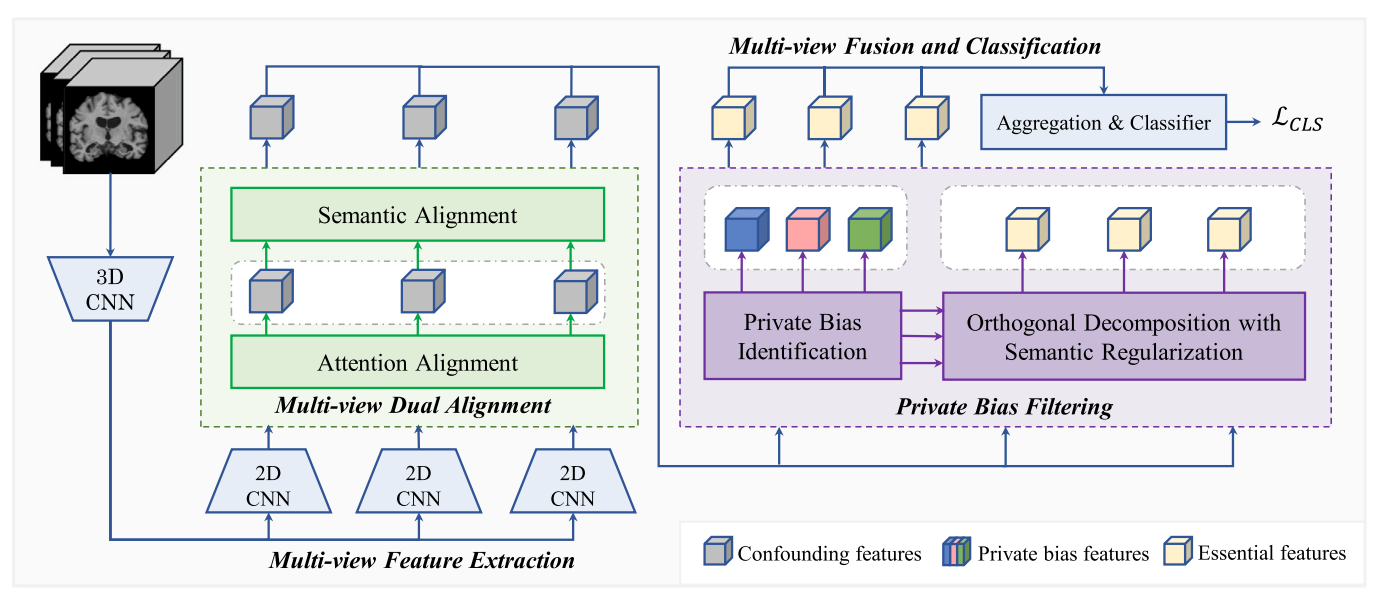 Interpretable multi-view fusion network via multi-view dual alignment and private bias filtering for Alzheimer’s disease analysisJinghao Xu, Chenxi Yuan, Yi Jing, and 3 more authorsInformation Fusion, 2025中科院JCR一区
Interpretable multi-view fusion network via multi-view dual alignment and private bias filtering for Alzheimer’s disease analysisJinghao Xu, Chenxi Yuan, Yi Jing, and 3 more authorsInformation Fusion, 2025中科院JCR一区Structural magnetic resonance imaging (sMRI) combined with multi-view learning has been preliminarily explored in Alzheimer’s disease (AD) analysis. However, existing methods usually face two key limitations: (i) they fail to fully exploit the inherent consistency of multiple views to design constraints for alignment and feature normalization; (ii) they lack effective mechanisms to separate discriminative information from view-specific noise. Hence, the fused representation may fail to effectively preserve cross-view complementary information, or even contain redundant noise, which often limits the performance of the final model. To address these challenges, we propose an innovative Alignment-Filtering-Fusion Network (AFFNet), which consists of four collaborative modules. Specifically, the multi-view feature extraction module integrates 3D and 2D convolutional networks to capture spatial structural information and extract multi-view features. The multi-view dual alignment module fully exploits the inherent supervision in multi-view data by introducing dual constraints of semantic and attention alignment, ensuring the regularization of complementary multi-view information while enhancing cross-view consistency. The private bias filtering module employs cross-view contrastive loss, orthogonal decomposition, and semantic regularization to identify and separate view-specific noise unrelated to the classification task, improving feature discriminability and laying the foundation for subsequent fusion. Finally, the multi-view fusion and classification module performs mean fusion on the aligned and filtered multi-view features to achieve complementary information integration for AD classification. Extensive experiments on widely used ADNI and AIBL datasets demonstrate that AFFNet significantly outperforms existing methods in AD classification accuracy and model interpretability. All data list and source codes are available at: https://github.com/nollexu/AFFNet.
@article{xu2025interpretable2, author = {Xu, Jinghao and Yuan, Chenxi and Jing, Yi and Shang, Huifang and Shi, Xiaoshuang and Zhu, Xiaofeng}, journal = {Information Fusion}, note = {中科院JCR一区}, pages = {103579}, title = {Interpretable multi-view fusion network via multi-view dual alignment and private bias filtering for Alzheimer’s disease analysis}, year = {2025}, }
2024
- ICML
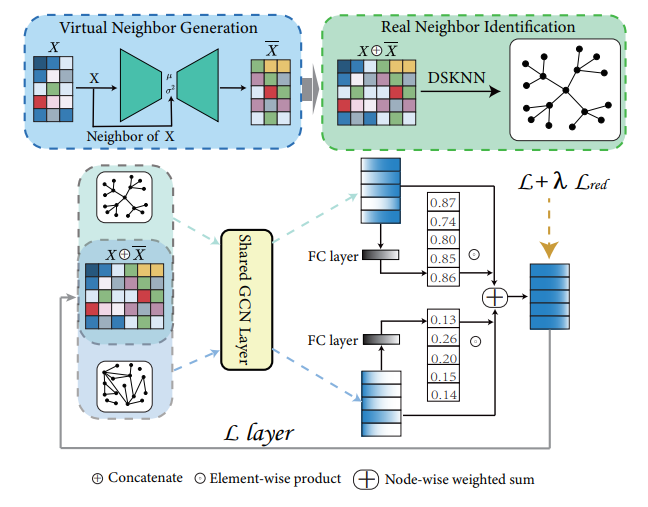 On Which Nodes Does GCN Fail? Enhancing GCN From the Node PerspectiveJincheng Huang, Jialie Shen, Xiaoshuang Shi*, and 1 more authorIn International Conference on Machine Learning (ICML), 2024CCF-A
On Which Nodes Does GCN Fail? Enhancing GCN From the Node PerspectiveJincheng Huang, Jialie Shen, Xiaoshuang Shi*, and 1 more authorIn International Conference on Machine Learning (ICML), 2024CCF-AThe label smoothness assumption is at the core of Graph Convolutional Networks (GCNs): nodes in a local region have similar labels. Thus, GCN performs local feature smoothing operation to adhere to this assumption. However, there exist some nodes whose labels obtained by feature smoothing conflict with the label smoothness assumption. We find that the label smoothness assumption and the process of feature smoothing are both problematic on these nodes, and call these nodes out of GCN’s control (OOC nodes). In this paper, first, we design the corresponding algorithm to locate the OOC nodes, then we summarize the characteristics of OOC nodes that affect their representation learning, and based on their characteristics, we present DaGCN, an efficient framework that can facilitate the OOC nodes. Extensive experiments verify the superiority of the proposed method and demonstrate that current advanced GCNs are improvements specifically on OOC nodes; the remaining nodes under GCN’s control (UC nodes) are already optimally represented by vanilla GCN on most datasets.
@inproceedings{huang2024on, author = {Huang, Jincheng and Shen, Jialie and Shi, Xiaoshuang and Zhu, Xiaofeng}, booktitle = {International Conference on Machine Learning (ICML)}, note = {CCF-A}, title = {On Which Nodes Does GCN Fail? Enhancing GCN From the Node Perspective}, year = {2024} } - CVPR
 ACT-Diffusion: Efficient Adversarial Consistency Training for One-step Diffusion ModelsFei Kong, Jinhao Duan, Lichao Sun, and 6 more authorsIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024CCF-A
ACT-Diffusion: Efficient Adversarial Consistency Training for One-step Diffusion ModelsFei Kong, Jinhao Duan, Lichao Sun, and 6 more authorsIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024CCF-AThough diffusion models excel in image generation, their step-by-step denoising leads to slow generation speeds. Consistency training addresses this issue with single-step sampling but often produces lower-quality generations and requires high training costs. In this paper, we show that optimizing consistency training loss minimizes the Wasserstein distance between target and generated distributions. As timestep increases, the upper bound accumulates previous consistency training losses. Therefore, larger batch sizes are needed to reduce both current and accumulated losses. We propose Adversarial Consistency Training (ACT), which directly minimizes the Jensen-Shannon (JS) divergence between distributions at each timestep using a discriminator. Theoretically, ACT enhances generation quality, and convergence. By incorporating a discriminator into the consistency training framework, our method achieves improved FID scores on CIFAR10 and ImageNet 64×64 and LSUN Cat 256×256 datasets, retains zero-shot image inpainting capabilities, and uses less than 1/6 of the original batch size and fewer than 1/2 of the model parameters and training steps compared to the baseline method, this leads to a substantial reduction in resource consumption. Our code is available:https://github.com/kong13661/ACT
@inproceedings{kong2024act, author = {Kong, Fei and Duan, Jinhao and Sun, Lichao and Cheng, Hao and Xu, Renjing and Shen, Hengtao and Zhu, Xiaofeng and Shi, Xiaoshuang and Xu, Kaidi}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, note = {CCF-A}, pages = {8890--8899}, title = {ACT-Diffusion: Efficient Adversarial Consistency Training for One-step Diffusion Models}, year = {2024} } - ACM MM
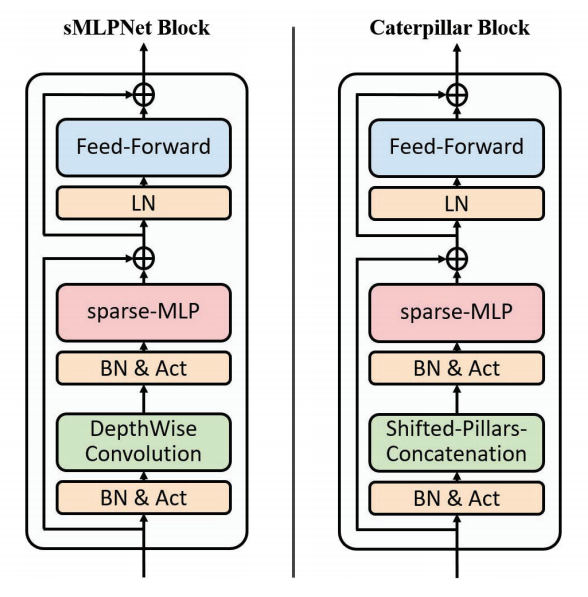 Caterpillar: A Pure-MLP Architecture with Shifted-Pillars-ConcatenationJin Sun, Xiaoshuang Shi*, Zhiyuan Wang, and 3 more authorsIn Proceedings of the ACM International Conference on Multimedia (ACM MM), 2024CCF-A
Caterpillar: A Pure-MLP Architecture with Shifted-Pillars-ConcatenationJin Sun, Xiaoshuang Shi*, Zhiyuan Wang, and 3 more authorsIn Proceedings of the ACM International Conference on Multimedia (ACM MM), 2024CCF-AModeling in Computer Vision has evolved to MLPs. Vision MLPs naturally lack local modeling capability, to which the simplest treatment is combined with convolutional layers. Convolution, famous for its sliding window scheme, also suffers from this scheme of redundancy and low computational efficiency. In this paper, we seek to dispense with the windowing scheme and introduce a more elaborate and effective approach to exploiting locality. To this end, we propose a new MLP module, namely Shifted-Pillars-Concatenation (SPC), that consists of two steps of processes: (1) Pillars-Shift, which generates four neighboring maps by shifting the input image along four directions, and (2) Pillars-Concatenation, which applies linear transformations and concatenation on the maps to aggregate local features. SPC module offers superior local modeling power and performance gains, making it a promising alternative to the convolutional layer. Then, we build a pure-MLP architecture called Caterpillar by replacing the convolutional layer with the SPC module in a hybrid model of sMLPNet. Extensive experiments show Caterpillar’s excellent performance and scalability on both ImageNet-1K and small-scale classification benchmarks.
@inproceedings{sun2024caterpillar, author = {Sun, Jin and Shi, Xiaoshuang and Wang, Zhiyuan and Xu, Kaidi and Shen, Heng Tao and Zhu, Xiaofeng}, booktitle = {Proceedings of the ACM International Conference on Multimedia (ACM MM)}, note = {CCF-A}, pages = {7123--7132}, title = {Caterpillar: A Pure-MLP Architecture with Shifted-Pillars-Concatenation}, year = {2024} } - PR
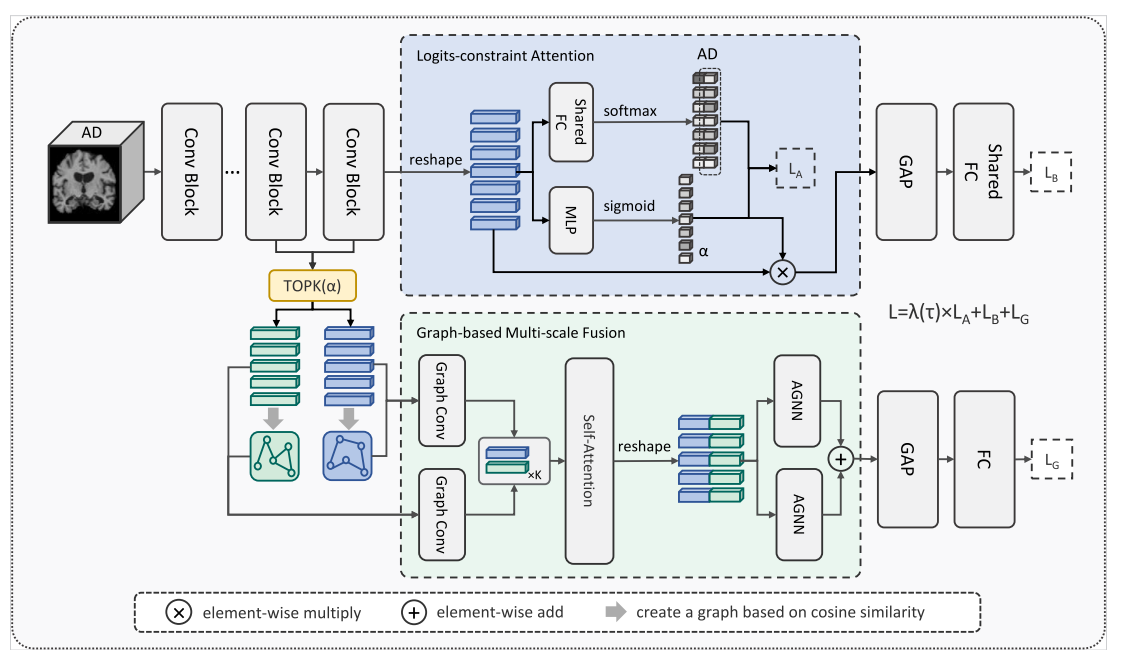 Interpretable medical deep framework by logits-constraint attention guiding graph-based multi-scale fusion for Alzheimer’s disease analysisJinghao Xu, Chenxi Yuan, Xiaochuan Ma, and 3 more authorsPattern Recognition, 2024中科院JCR一区
Interpretable medical deep framework by logits-constraint attention guiding graph-based multi-scale fusion for Alzheimer’s disease analysisJinghao Xu, Chenxi Yuan, Xiaochuan Ma, and 3 more authorsPattern Recognition, 2024中科院JCR一区Deep learning using structural MRI has been widely applied to early diagnosis study of Alzheimer’s disease. Among existing methods, attention-based 3D subject-level methods can not only provide diagnosis results but also interpret the significant brain regions, thereby attracting considerable attention. However, the performance of previous attention-based methods might be still restricted by: (i) the gap between attention scores and semantic significant regions; (ii) using only single-scale features or simply fusing multi-scale information by addition or concatenation for classification decision-making. To overcome these two issues, we propose an innovative dual-branch model called LA-GMF, which consists of two major modules: logits-constraint attention (LA) and graph-based multi-scale fusion (GMF). The LA module is designed to guide the model to focus on key areas to enhance the diagnostic performance of local lesions, by reducing the inconsistency between attention scores and class prediction probabilities. Meanwhile, by combining the graph neural network and the self-attention mechanism, the GMF module not only introduces the interaction between patches, but also explores the correlation and complementarity between features at different scales, thereby extracting feature representations more comprehensively. Experiments on the popular ADNI and AIBL datasets validate the potential of our model in boosting early AD diagnosis accuracy. Additionally, our interpretation experiments demonstrate the superior interpretability performance of the proposed method over recent state-of-the-art attention-based methods. Our source codes are released at: https://github.com/nollexu/LA-GMF.
@article{xu2024interpretable, author = {Xu, Jinghao and Yuan, Chenxi and Ma, Xiaochuan and Shang, Huifang and Shi, Xiaoshuang and Zhu, Xiaofeng}, journal = {Pattern Recognition}, note = {中科院JCR一区}, pages = {110450}, title = {Interpretable medical deep framework by logits-constraint attention guiding graph-based multi-scale fusion for Alzheimer’s disease analysis}, volume = {152}, year = {2024}, } - TNNLS
 Feature Noise Boosts DNN Generalization Under Label NoiseLu Zeng, Xuan Chen, Xiaoshuang Shi*, and 1 more authorIEEE Transactions on Neural Networks and Learning Systems, 2024中科院JCR一区
Feature Noise Boosts DNN Generalization Under Label NoiseLu Zeng, Xuan Chen, Xiaoshuang Shi*, and 1 more authorIEEE Transactions on Neural Networks and Learning Systems, 2024中科院JCR一区The presence of label noise in the training data has a profound impact on the generalization of deep neural networks (DNNs). In this study, we introduce and theoretically demonstrate a simple feature noise (FN) method, which directly adds noise to the features of training data and can enhance the generalization of DNNs under label noise. Specifically, we conduct theoretical analyses to reveal that label noise leads to weakened DNN generalization by loosening the generalization bound, and FN results in better DNN generalization by imposing an upper bound on the mutual information between the model weights and the features, which constrains the generalization bound. Furthermore, we conduct a qualitative analysis to discuss the ideal type of FN that obtains good label noise generalization. Finally, extensive experimental results on several popular datasets demonstrate that the FN method can significantly enhance the label noise generalization of state-of-the-art methods. The source codes of the FN method are available on https://github.com/zlzenglu/FN.
@article{zeng2024feature, author = {Zeng, Lu and Chen, Xuan and Shi, Xiaoshuang and Shen, Heng Tao}, journal = {IEEE Transactions on Neural Networks and Learning Systems}, note = {中科院JCR一区}, title = {Feature Noise Boosts DNN Generalization Under Label Noise}, year = {2024}, }
2023
- MICCAI
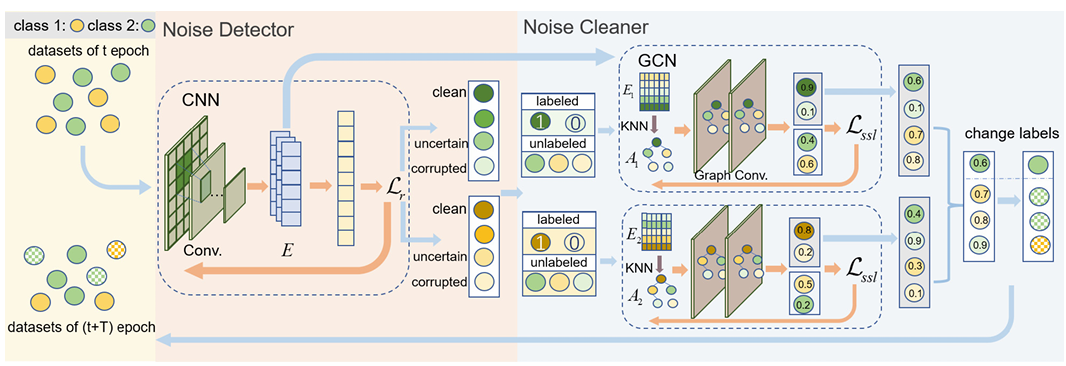 Co-assistant Networks for Label CorrectionXuan Chen, Weiheng Fu, Tian Li, and 3 more authorsIn International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2023CCF-B
Co-assistant Networks for Label CorrectionXuan Chen, Weiheng Fu, Tian Li, and 3 more authorsIn International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2023CCF-BThe presence of corrupted labels is a common problem in the medical image datasets due to the difficulty of annotation. Meanwhile, corrupted labels might significantly deteriorate the performance of deep neural networks (DNNs), which have been widely applied to medical image analysis. To alleviate this issue, in this paper, we propose a novel framework, namely Co-assistant Networks for Label Correction (CNLC), to simultaneously detect and correct corrupted labels. Specifically, the proposed framework consists of two modules, i.e., noise detector and noise cleaner. The noise detector designs a CNN-based model to distinguish corrupted labels from all samples, while the noise cleaner investigates class-based GCNs to correct the detected corrupted labels. Moreover, we design a new bi-level optimization algorithm to optimize our proposed objective function. Extensive experiments on three popular medical image datasets demonstrate the superior performance of our framework over recent state-of-the-art methods. Source codes of the proposed method are available on https://github.com/shannak-chen/CNLC
@inproceedings{chen2023co, author = {Chen, Xuan and Fu, Weiheng and Li, Tian and Shi, Xiaoshuang and Shen, Hengtao and Zhu, Xiaofeng}, booktitle = {International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI)}, note = {CCF-B}, pages = {159--168}, title = {Co-assistant Networks for Label Correction}, year = {2023}, } - IJCAI
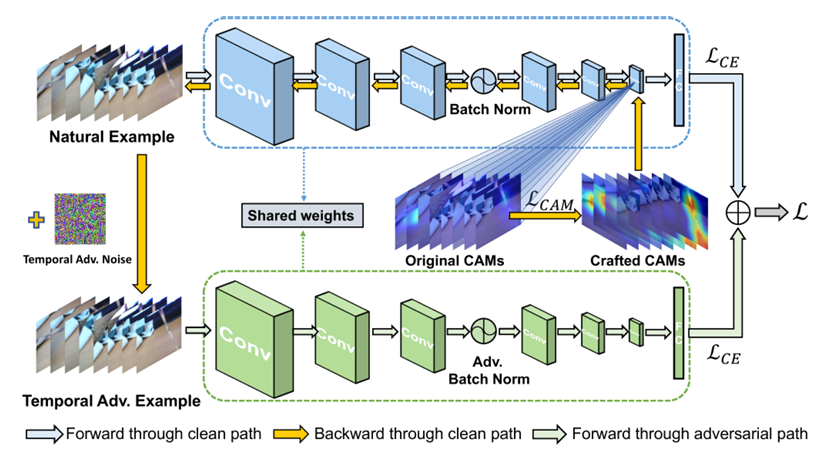 Improve video representation with temporal adversarial augmentationJinhao Duan, Quanfu Fan, Hao Cheng, and 2 more authorsIn International Joint Conference on Artificial Intelligence (IJCAI), 2023CCF-A
Improve video representation with temporal adversarial augmentationJinhao Duan, Quanfu Fan, Hao Cheng, and 2 more authorsIn International Joint Conference on Artificial Intelligence (IJCAI), 2023CCF-ARecent works reveal that adversarial augmentation benefits the generalization of neural networks (NNs) if used in an appropriate manner. In this paper, we introduce Temporal Adversarial Augmentation (TA), a novel video augmentation technique that utilizes temporal attention. Unlike conventional adversarial augmentation, TA is specifically designed to shift the attention distributions of neural networks with respect to video clips by maximizing a temporal-related loss function. We demonstrate that TA will obtain diverse temporal views, which significantly affect the focus of neural networks. Training with these examples remedies the flaw of unbalanced temporal information perception and enhances the ability to defend against temporal shifts, ultimately leading to better generalization. To leverage TA, we propose Temporal Video Adversarial Fine-tuning (TAF) framework for improving video representations. TAF is a model-agnostic, generic, and interpretability-friendly training strategy. We evaluate TAF with four powerful models (TSM, GST, TAM, and TPN) over three challenging temporal-related benchmarks (Something-something V1&V2 and diving48). Experimental results demonstrate that TAF effectively improves the test accuracy of these models with notable margins without introducing additional parameters or computational costs. As a byproduct, TAF also improves the robustness under out-of-distribution (OOD) settings. Code is available at https://github.com/jinhaoduan/TAF.
@inproceedings{duan2023improve, author = {Duan, Jinhao and Fan, Quanfu and Cheng, Hao and Shi, Xiaoshuang and Xu, Kaidi}, booktitle = {International Joint Conference on Artificial Intelligence (IJCAI)}, note = {CCF-A}, pages = {708--716}, title = {Improve video representation with temporal adversarial augmentation}, year = {2023}, } - MIA
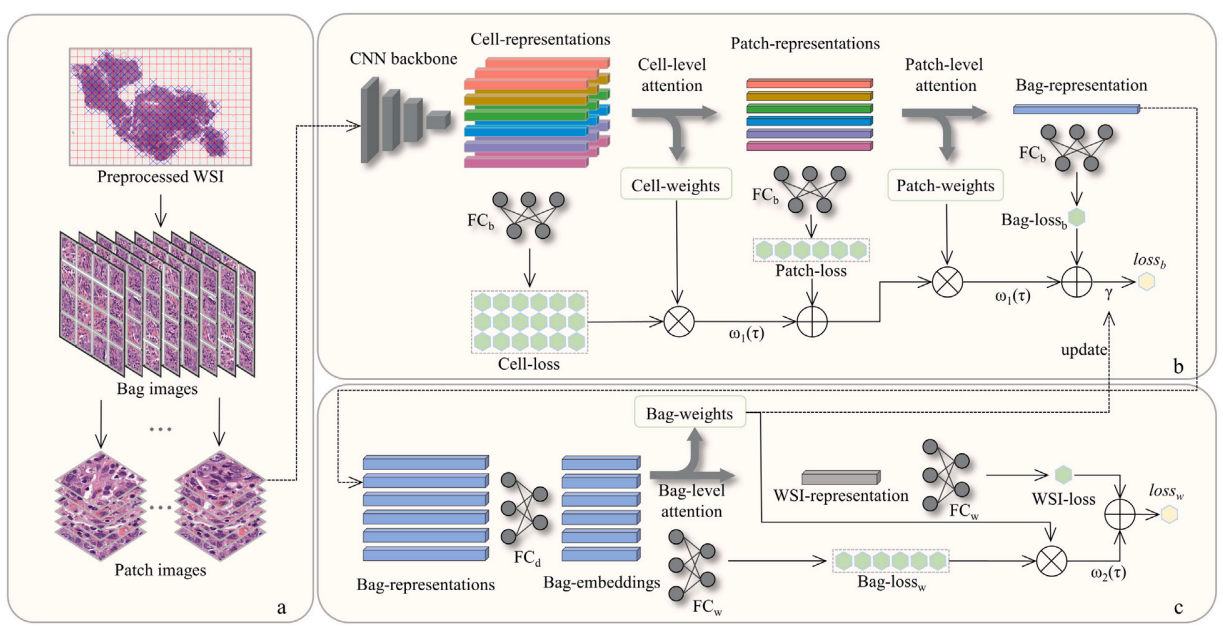 Multi-scale representation attention based deep multiple instance learning for gigapixel whole slide image analysisHangchen Xiang, Junyi Shen, Qingguo Yan, and 3 more authorsMedical Image Analysis, 2023中科院JCR一区
Multi-scale representation attention based deep multiple instance learning for gigapixel whole slide image analysisHangchen Xiang, Junyi Shen, Qingguo Yan, and 3 more authorsMedical Image Analysis, 2023中科院JCR一区Recently, convolutional neural networks (CNNs) directly using whole slide images (WSIs) for tumor diagnosis and analysis have attracted considerable attention, because they only utilize the slide-level label for model training without any additional annotations. However, it is still a challenging task to directly handle gigapixel WSIs, due to the billions of pixels and intra-variations in each WSI. To overcome this problem, in this paper, we propose a novel end-to-end interpretable deep MIL framework for WSI analysis, by using a two-branch deep neural network and a multi-scale representation attention mechanism to directly extract features from all patches of each WSI. Specifically, we first divide each WSI into bag-, patch- and cell-level images, and then assign the slide-level label to its corresponding bag-level images, so that WSI classification becomes a MIL problem. Additionally, we design a novel multi-scale representation attention mechanism, and embed it into a two-branch deep network to simultaneously mine the bag with a correct label, the significant patches and their cell-level information. Extensive experiments demonstrate the superior performance of the proposed framework over recent state-of-the-art methods, in term of classification accuracy and model interpretability. All source codes are released at: https://github.com/xhangchen/MRAN/.
@article{xiang2023multi, author = {Xiang, Hangchen and Shen, Junyi and Yan, Qingguo and Xu, Meilian and Shi, Xiaoshuang and Zhu, Xiaofeng}, journal = {Medical Image Analysis}, note = {中科院JCR一区}, pages = {102890}, title = {Multi-scale representation attention based deep multiple instance learning for gigapixel whole slide image analysis}, volume = {89}, year = {2023}, } - IPM
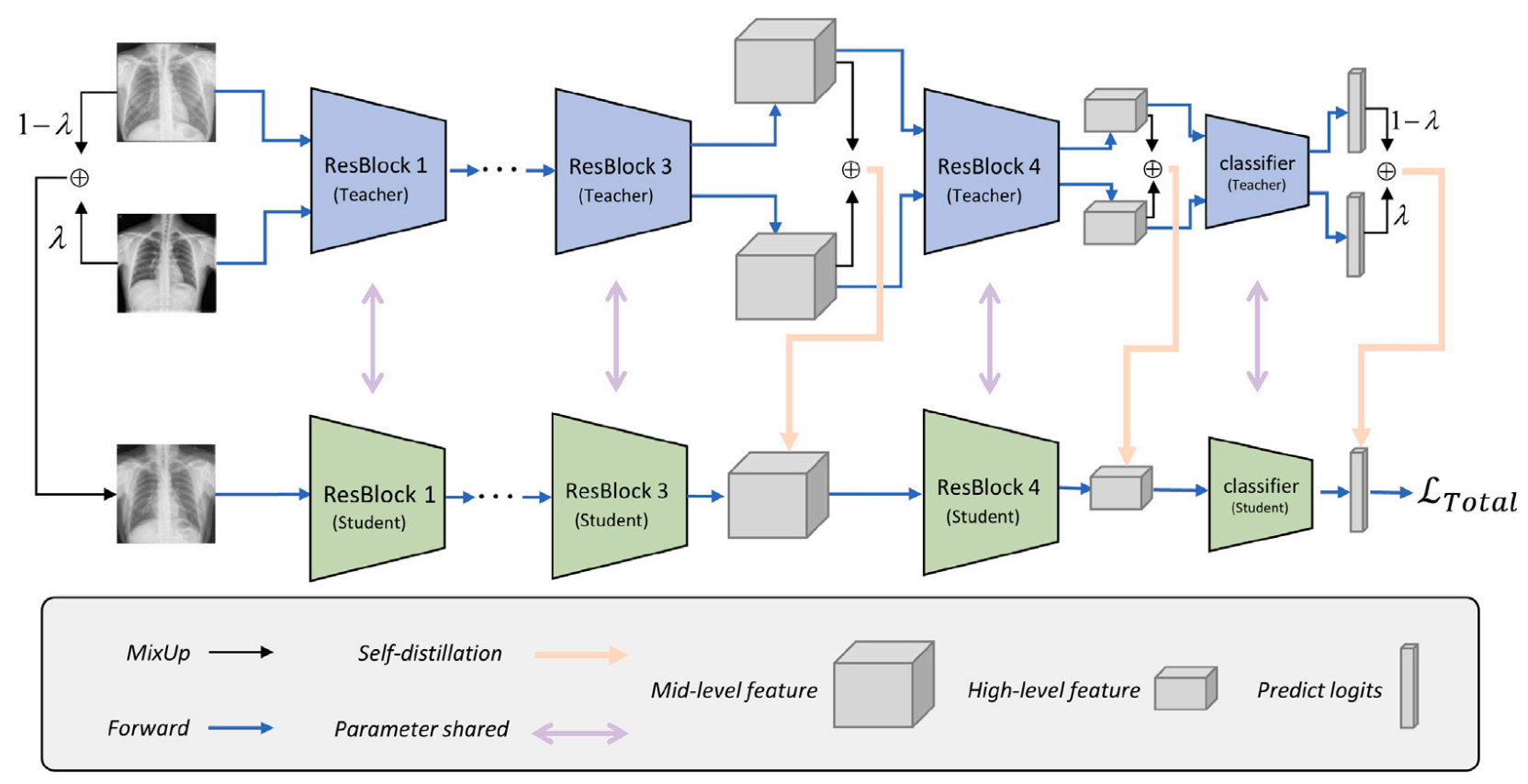 IGCNN-FC: Boosting interpretability and generalization of convolutional neural networks for few chest X-rays analysisMengmeng Zhan, Xiaoshuang Shi*, Fangqi Liu, and 1 more authorInformation Processing & Management, 2023中科院JCR一区
IGCNN-FC: Boosting interpretability and generalization of convolutional neural networks for few chest X-rays analysisMengmeng Zhan, Xiaoshuang Shi*, Fangqi Liu, and 1 more authorInformation Processing & Management, 2023中科院JCR一区Computer-aided diagnosis (CAD) with convolutional neural networks (CNNs) has been widely applied to assist doctors in medical image analysis. However, most of them often encounter two obstacles: (1) Data scarcity, because the advanced performance of CNNs heavily depends on a large amount of data, especially high-quality annotated ones. (2) Interpretability, CNNs cannot directly provide evidence related to the decision-making process to support their diagnosis results. To overcome these two obstacles, we propose an interpretable deep learning framework based on CNNs. Specifically, we introduce a multi-scale loss-based attention to leverage the mid- and high-level features to mine significant features for decision-making. Additionally, to better explore the semantic knowledge from training data, we utilize the mixup method to produce more annotated training images. Moreover, to boost model generalization capability, we employ the self-distillation to learn the knowledge generated from previous training epochs. Experiments on two benchmark Chest X-ray datasets demonstrate the effectiveness of the proposed framework with superior performance over recent SOTA methods, with boosting model interpretability.
@article{zhan2023igcnn, author = {Zhan, Mengmeng and Shi, Xiaoshuang and Liu, Fangqi and Hu, Rongyao}, journal = {Information Processing & Management}, note = {中科院JCR一区}, pages = {103258}, title = {IGCNN-FC: Boosting interpretability and generalization of convolutional neural networks for few chest X-rays analysis}, volume = {60}, year = {2023}, }
2022
- TETCI
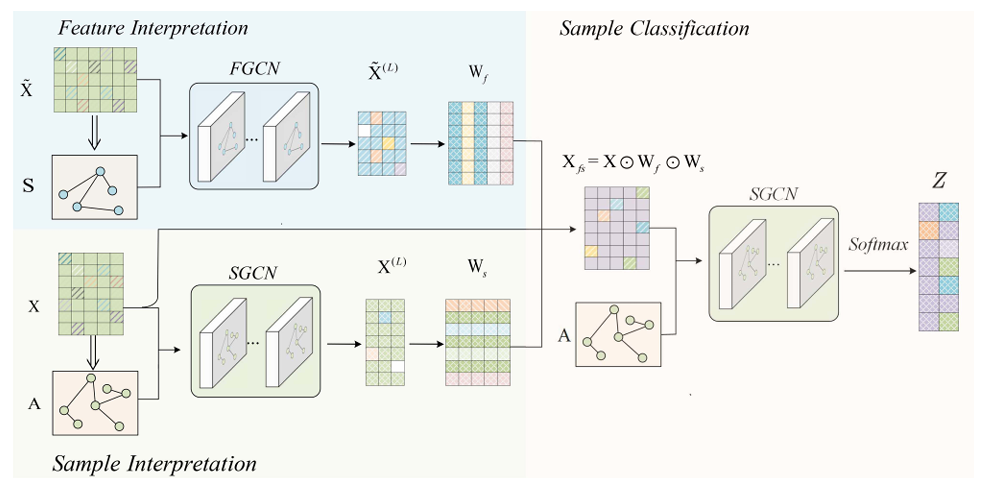 FSNet: Dual Interpretable Graph Convolutional Network for Alzheimer’s Disease AnalysisHengxin Li+, Xiaoshuang Shi+, Xiaofeng Zhu, and 2 more authorsIEEE Transactions on Emerging Topics in Computational Intelligence, 2022中科院JCR二区
FSNet: Dual Interpretable Graph Convolutional Network for Alzheimer’s Disease AnalysisHengxin Li+, Xiaoshuang Shi+, Xiaofeng Zhu, and 2 more authorsIEEE Transactions on Emerging Topics in Computational Intelligence, 2022中科院JCR二区Graph Convolutional Networks (GCNs) are widely used in medical images diagnostic research, because they can automatically learn powerful and robust feature representations. However, their performance might be significantly deteriorated by trivial or corrupted medical features and samples. Moreover, existing methods cannot simultaneously interpret the significant features and samples. To overcome these limitations, in this paper, we propose a novel dual interpretable graph convolutional network, namely FSNet, to simultaneously select significant features and samples, so as to boost model performance for medical diagnosis and interpretation. Specifically, the proposed network consists of three modules, two of which leverage one simple yet effective sparse mechanism to obtain feature and sample weight matrices for interpreting features and samples, respectively, and the third one is utilized for medical diagnosis. Extensive experiments on the Alzheimer’s Disease Neuroimaging Initiative (ADNI) datasets demonstrate the superior classification performance and interpretability over the recent state-of-the-art methods.
@article{li2022fsnet, author = {Li+, Hengxin and Shi+, Xiaoshuang and Zhu, Xiaofeng and Wang, Shuihua and Zhang, Zheng}, journal = {IEEE Transactions on Emerging Topics in Computational Intelligence}, note = {中科院JCR二区}, title = {FSNet: Dual Interpretable Graph Convolutional Network for Alzheimer's Disease Analysis}, year = {2022}, } - AAAI
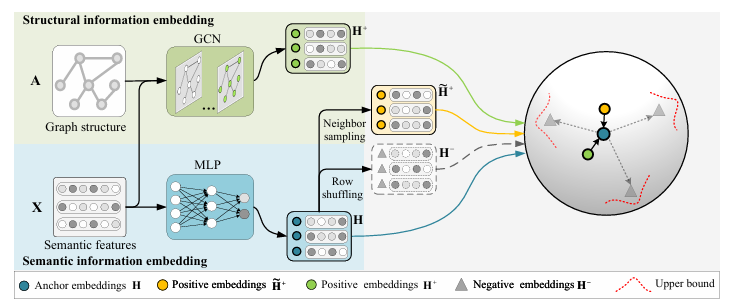 Simple Unsupervised Graph Representation LearningYujie Mo, Liang Peng, Jie Xu, and 2 more authorsIn AAAI Conference on Artificial Intelligence, 2022CCF-A
Simple Unsupervised Graph Representation LearningYujie Mo, Liang Peng, Jie Xu, and 2 more authorsIn AAAI Conference on Artificial Intelligence, 2022CCF-AIn this paper, we propose a simple unsupervised graph representation learning method to conduct effective and efficient contrastive learning. Specifically, the proposed multiplet loss explores the complementary information between the structural information and neighbor information to enlarge the inter-class variation, as well as adds an upper bound loss to achieve the finite distance between positive embeddings and anchor embeddings for reducing the intra-class variation. As a result, both enlarging inter-class variation and reducing intra-class variation result in small generalization error, thereby obtaining an effective model. Furthermore, our method removes widely used data augmentation and discriminator from previous graph contrastive learning methods, meanwhile available to output low-dimensional embeddings, leading to an efficient model. Experimental results on various real-world datasets demonstrate the effectiveness and efficiency of our method, compared to state-of-the-art methods. The source codes are released at https://github.com/YujieMo/SUGRL.
@inproceedings{mo2022simple, author = {Mo, Yujie and Peng, Liang and Xu, Jie and Shi, Xiaoshuang and Zhu, Xiaofeng}, booktitle = {AAAI Conference on Artificial Intelligence}, note = {CCF-A}, title = {Simple Unsupervised Graph Representation Learning}, year = {2022}, } - TNNLS
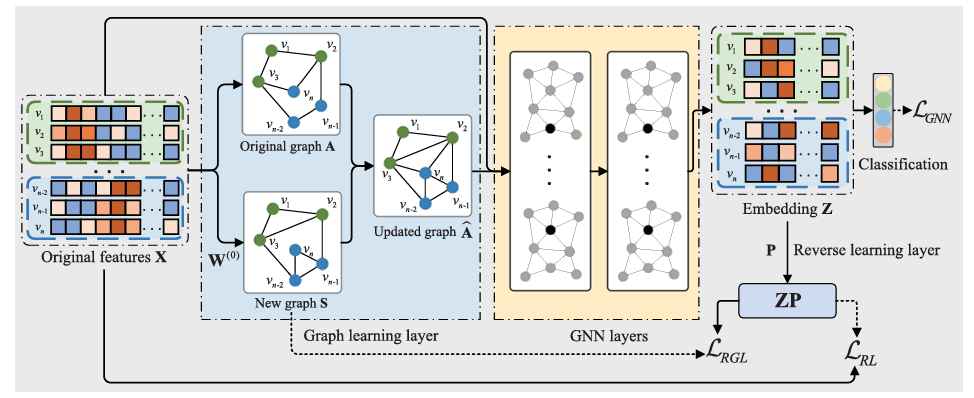 Reverse Graph Learning for Graph Neural NetworkLiang Peng, Rongyao Hu, Fei Kong, and 4 more authorsIEEE Transactions on Neural Networks and Learning Systems, 2022中科院JCR一区
Reverse Graph Learning for Graph Neural NetworkLiang Peng, Rongyao Hu, Fei Kong, and 4 more authorsIEEE Transactions on Neural Networks and Learning Systems, 2022中科院JCR一区Graph neural networks (GNNs) conduct feature learning by taking into account the local structure preservation of the data to produce discriminative features, but need to address the following issues, i.e., 1) the initial graph containing faulty and missing edges often affect feature learning and 2) most GNN methods suffer from the issue of out-of-example since their training processes do not directly generate a prediction model to predict unseen data points. In this work, we propose a reverse GNN model to learn the graph from the intrinsic space of the original data points as well as to investigate a new out-of-sample extension method. As a result, the proposed method can output a high-quality graph to improve the quality of feature learning, while the new method of out-of-sample extension makes our reverse GNN method available for conducting supervised learning and semi-supervised learning. Experimental results on real-world datasets show that our method outputs competitive classification performance, compared to state-of-the-art methods, in terms of semi-supervised node classification, out-of-sample extension, random edge attack, link prediction, and image retrieval.
@article{peng2022reverse, author = {Peng, Liang and Hu, Rongyao and Kong, Fei and Gan, Jiangzhang and Mo, Yujie and Shi, Xiaoshuang and Zhu, Xiaofeng}, journal = {IEEE Transactions on Neural Networks and Learning Systems}, note = {中科院JCR一区}, title = {Reverse Graph Learning for Graph Neural Network}, year = {2022}, } - PR
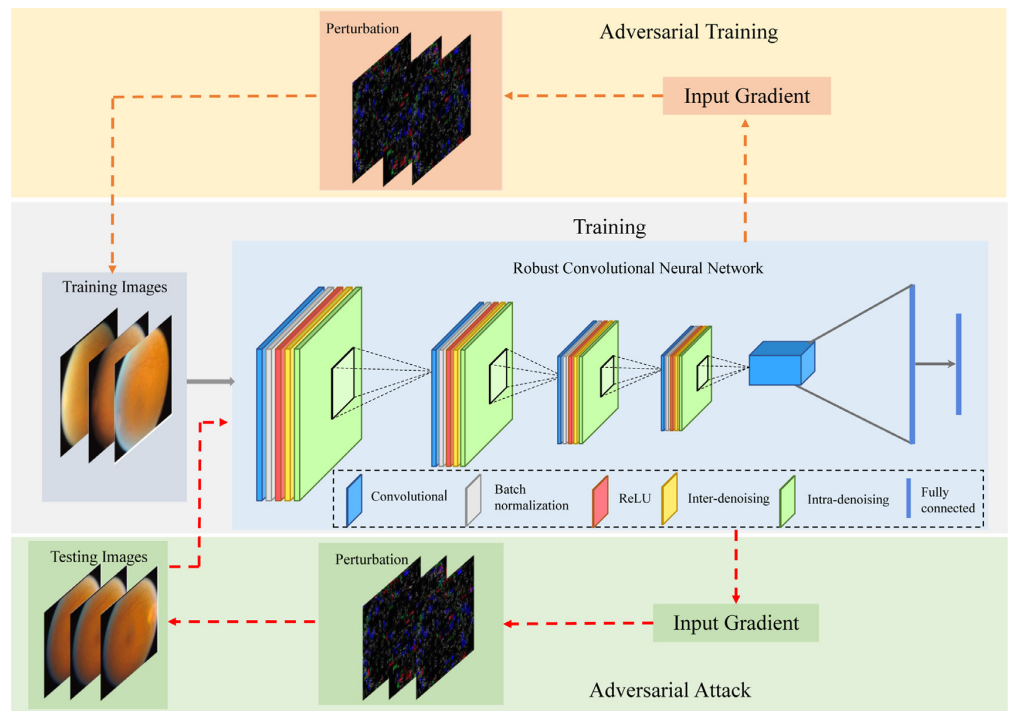 Robust convolutional neural networks against adversarial attacks on medical imagesXiaoshuang Shi, Yifan Peng, and et al. ChenPattern Recognition, 2022中科院JCR一区
Robust convolutional neural networks against adversarial attacks on medical imagesXiaoshuang Shi, Yifan Peng, and et al. ChenPattern Recognition, 2022中科院JCR一区Convolutional neural networks (CNNs) have been widely applied to medical images. However, medical images are vulnerable to adversarial attacks by perturbations that are undetectable to human experts. This poses significant security risks and challenges to CNN-based applications in clinic practice. In this work, we quantify the scale of adversarial perturbation imperceptible to clinical practitioners and investigate the cause of the vulnerability in CNNs. Specifically, we discover that noise (i.e., irrelevant or corrupted discriminative information) in medical images might be a key contributor to performance deterioration of CNNs against adversarial perturbations, as noisy features are learned unconsciously by CNNs in feature representations and magnified by adversarial perturbations. In response, we propose a novel defense method by embedding sparsity denoising operators in CNNs for improved robustness. Tested with various state-of-the-art attacking methods on two distinct medical image modalities, we demonstrate that the proposed method can successfully defend against those unnoticeable adversarial attacks by retaining as much as over 90% of its original performance. We believe our findings are critical for improving and deploying CNN-based medical applications in real-world scenarios.
@article{shi2022robust, author = {Shi, Xiaoshuang and Peng, Yifan and Chen, Qingyu, et al.}, journal = {Pattern Recognition}, note = {中科院JCR一区}, pages = {108923}, title = {Robust convolutional neural networks against adversarial attacks on medical images}, volume = {132}, year = {2022}, } - PR
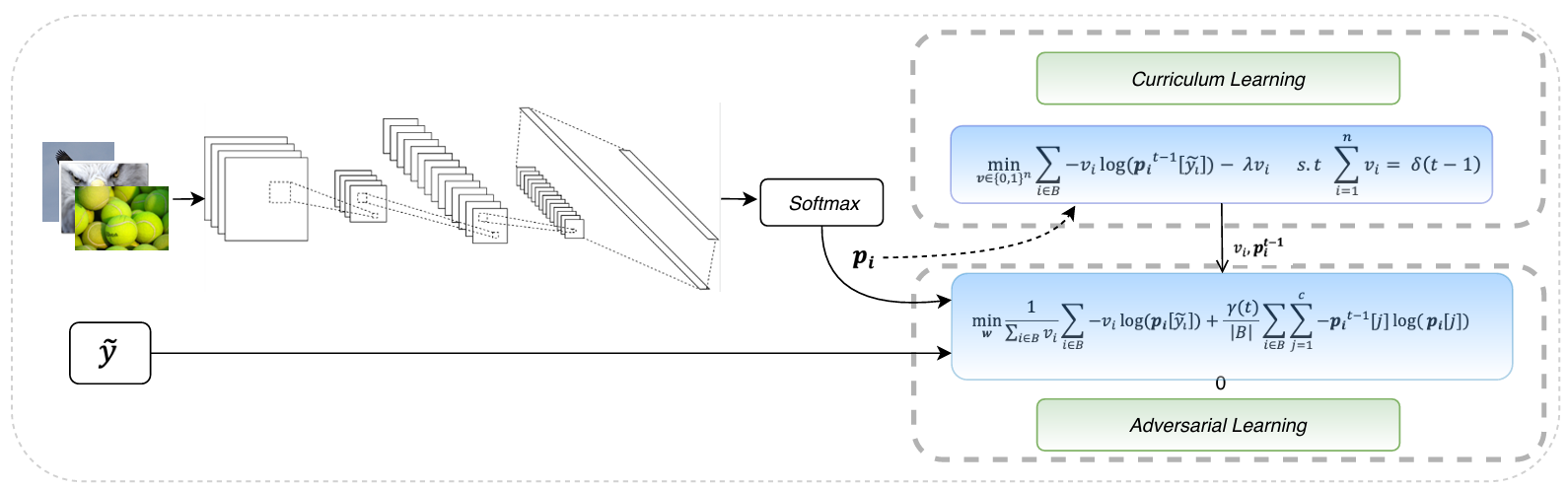 Self-paced Resistance Learning against Overfitting on Noisy LabelsXiaoshuang Shi, Zhenhua Guo, Kang Li, and 2 more authorsPattern Recognition, 2022中科院JCR一区
Self-paced Resistance Learning against Overfitting on Noisy LabelsXiaoshuang Shi, Zhenhua Guo, Kang Li, and 2 more authorsPattern Recognition, 2022中科院JCR一区Noisy labels composed of correct and corrupted ones are pervasive in practice. They might significantly deteriorate the performance of convolutional neural networks (CNNs), because CNNs are easily overfitted on corrupted labels. To address this issue, inspired by an observation, deep neural networks might first memorize the probably correct-label data and then corrupt-label samples, we propose a novel yet simple self-paced resistance framework to resist corrupted labels, without using any clean validation data. The proposed framework first utilizes the memorization effect of CNNs to learn a curriculum, which contains confident samples and provides meaningful supervision for other training samples. Then it adopts selected confident samples and a proposed resistance loss to update model parameters; the resistance loss tends to smooth model parameters’ update or attain equivalent prediction over each class, thereby resisting model overfitting on corrupted labels. Finally, we unify these two modules into a single loss function and optimize it in an alternative learning. Extensive experiments demonstrate the significantly superior performance of the proposed framework over recent state-of-the-art methods on noisy-label data. Source codes of the proposed method are available on https://github.com/xsshi2015/Self-paced-Resistance-Learning.
@article{shi2022self, author = {Shi, Xiaoshuang and Guo, Zhenhua and Li, Kang and Liang, Yun and Zhu, Xiaofeng}, journal = {Pattern Recognition}, note = {中科院JCR一区}, pages = {109080}, title = {Self-paced Resistance Learning against Overfitting on Noisy Labels}, year = {2022}, } - MICCAI
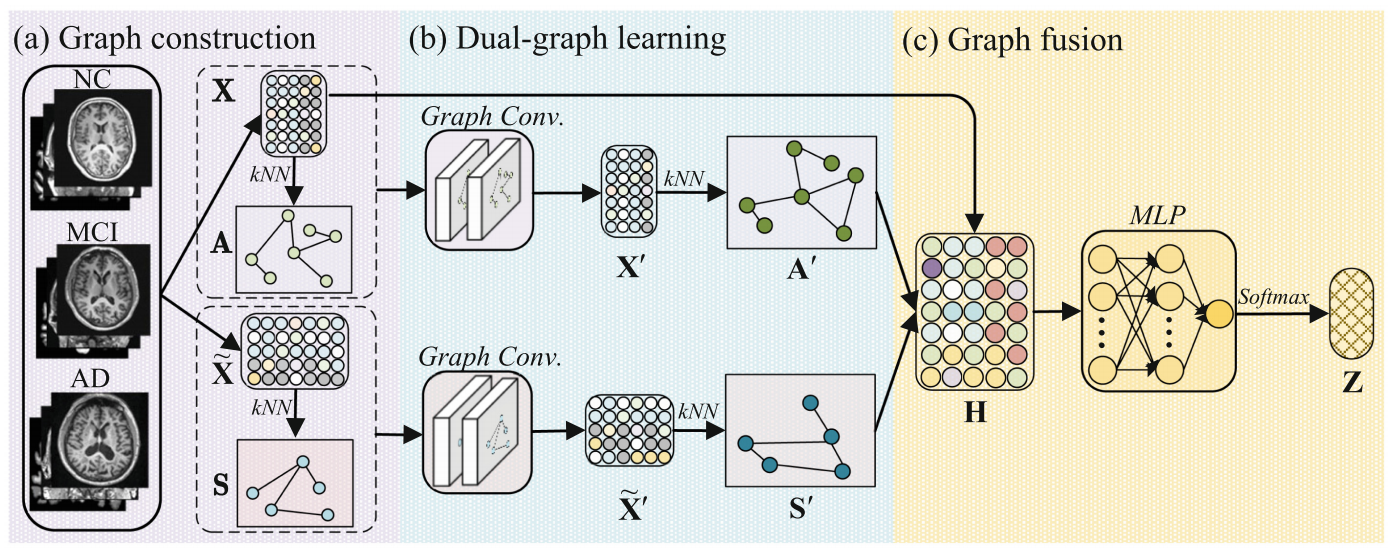 Dual-graph learning convolutional networks for interpretable alzheimer’s disease diagnosisTingsong Xiao, Lu Zeng, Xiaoshuang Shi*, and 2 more authorsIn International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2022CCF-B
Dual-graph learning convolutional networks for interpretable alzheimer’s disease diagnosisTingsong Xiao, Lu Zeng, Xiaoshuang Shi*, and 2 more authorsIn International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2022CCF-BIn this paper, we propose a dual-graph learning convolutional network (dGLCN) to achieve interpretable Alzheimer’s disease (AD) diagnosis, by jointly investigating subject graph learning and feature graph learning in the graph convolution network (GCN) framework. Specifically, we first construct two initial graphs to consider both the subject diversity and the feature diversity. We further fuse these two initial graphs into the GCN framework so that they can be iteratively updated (i.e., dual-graph learning) while conducting representation learning. As a result, the dGLCN achieves interpretability in both subjects and brain regions through the subject importance and the feature importance, and the generalizability by overcoming the issues, such as limited subjects and noisy subjects. Experimental results on the Alzheimer’s disease neuroimaging initiative (ADNI) datasets show that our dGLCN outperforms all comparison methods for binary classification. The codes of dGLCN are available on https://github.com/xiaotingsong/dGLCN .
@inproceedings{xiao2022dual, author = {Xiao, Tingsong and Zeng, Lu and Shi, Xiaoshuang and Zhu, Xiaofeng and Wu, Guorong}, booktitle = {International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI)}, note = {CCF-B}, pages = {406--415}, title = {Dual-graph learning convolutional networks for interpretable alzheimer’s disease diagnosis}, year = {2022}, } - AAAI
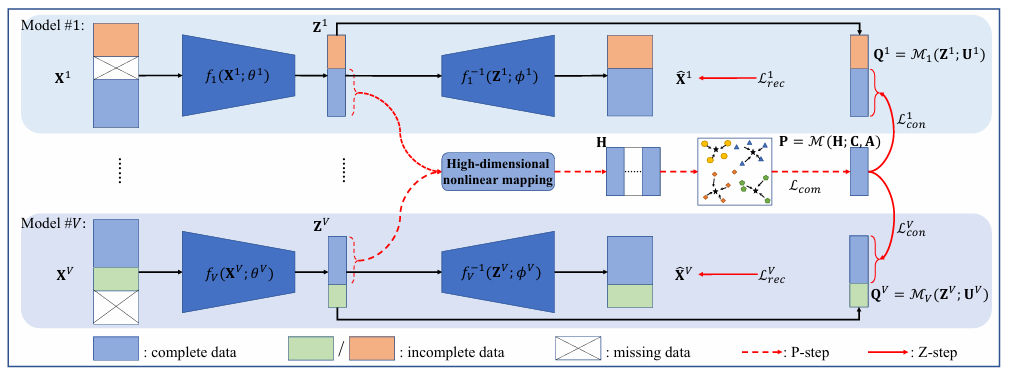 Deep Incomplete Multi-View Clustering via Mining Cluster ComplementarityJie Xu, Chao Li, Yazhou Ren*, and 4 more authorsIn AAAI Conference on Artificial Intelligence, 2022CCF-A
Deep Incomplete Multi-View Clustering via Mining Cluster ComplementarityJie Xu, Chao Li, Yazhou Ren*, and 4 more authorsIn AAAI Conference on Artificial Intelligence, 2022CCF-AIncomplete multi-view clustering (IMVC) is an important unsupervised approach to group the multi-view data containing missing data in some views. Previous IMVC methods suffer from the following issues: (1) the inaccurate imputation or padding for missing data negatively affects the clustering performance, (2) the quality of features after fusion might be interfered by the low-quality views, especially the inaccurate imputed views. To avoid these issues, this work presents an imputation-free and fusion-free deep IMVC framework. First, the proposed method builds a deep embedding feature learning and clustering model for each view individually. Our method then nonlinearly maps the embedding features of complete data into a high-dimensional space to discover linear separability. Concretely, this paper provides an implementation of the high-dimensional mapping as well as shows the mechanism to mine the multi-view cluster complementarity. This complementary information is then transformed to the supervised information with high confidence, aiming to achieve the multi-view clustering consistency for the complete data and incomplete data. Furthermore, we design an EM-like optimization strategy to alternately promote feature learning and clustering. Extensive experiments on real-world multi-view datasets demonstrate that our method achieves superior clustering performance over state-of-the-art methods.
@inproceedings{xu2022deep, author = {Xu, Jie and Li, Chao and Ren, Yazhou and Peng, Liang and Mo, Yujie and Shi, Xiaoshuang and Zhu, Xiaofeng}, booktitle = {AAAI Conference on Artificial Intelligence}, note = {CCF-A}, title = {Deep Incomplete Multi-View Clustering via Mining Cluster Complementarity}, year = {2022}, }
2021
- TIP
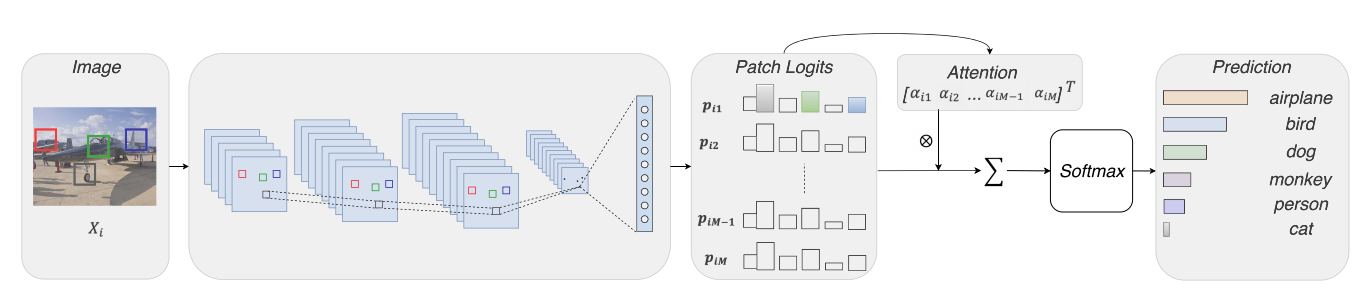 Loss-based Attention for Interpreting Image-level Prediction of Convolutional Neural NetworksXiaoshuang Shi, Fuyong Xing, Kaidi Xu, and 4 more authorsIEEE Transactions on Image Processing, 2021CCF-A
Loss-based Attention for Interpreting Image-level Prediction of Convolutional Neural NetworksXiaoshuang Shi, Fuyong Xing, Kaidi Xu, and 4 more authorsIEEE Transactions on Image Processing, 2021CCF-AAlthough deep neural networks have achieved great success on numerous large-scale tasks, poor interpretability is still a notorious obstacle for practical applications. In this paper, we propose a novel and general attention mechanism, loss-based attention, upon which we modify deep neural networks to mine significant image patches for explaining which parts determine the image decision-making. This is inspired by the fact that some patches contain significant objects or their parts for image-level decision. Unlike previous attention mechanisms that adopt different layers and parameters to learn weights and image prediction, the proposed loss-based attention mechanism mines significant patches by utilizing the same parameters to learn patch weights and logits (class vectors), and image prediction simultaneously, so as to connect the attention mechanism with the loss function for boosting the patch precision and recall. Additionally, different from previous popular networks that utilize max-pooling or stride operations in convolutional layers without considering the spatial relationship of features, the modified deep architectures first remove them to preserve the spatial relationship of image patches and greatly reduce their dependencies, and then add two convolutional or capsule layers to extract their features. With the learned patch weights, the image-level decision of the modified deep architectures is the weighted sum on patches. Extensive experiments on large-scale benchmark databases.
@article{shi2021loss, author = {Shi, Xiaoshuang and Xing, Fuyong and Xu, Kaidi and Chen, Pingjun and Liang, Yun and Lu, Zhiyong and Guo, Zhenhua}, journal = {IEEE Transactions on Image Processing}, note = {CCF-A}, pages = {1662--1675}, title = {Loss-based Attention for Interpreting Image-level Prediction of Convolutional Neural Networks}, volume = {30}, year = {2021} } - TIP
 A Scalable Optimization Mechanism for Pairwise based Discrete HashingXiaoshuang Shi, Fuyong Xing, Zizhao Zhang, and 3 more authorsIEEE Transactions on Image Processing, 2021中科院JCR一区
A Scalable Optimization Mechanism for Pairwise based Discrete HashingXiaoshuang Shi, Fuyong Xing, Zizhao Zhang, and 3 more authorsIEEE Transactions on Image Processing, 2021中科院JCR一区Maintaining the pairwise relationship among originally high-dimensional data into a low-dimensional binary space is a popular strategy to learn binary codes. One simple and intuitive method is to utilize two identical code matrices produced by hash functions to approximate a pairwise real label matrix. However, the resulting quartic problem in term of hash functions is difficult to directly solve due to the non-convex and non-smooth nature of the objective. In this paper, unlike previous optimization methods using various relaxation strategies, we aim to directly solve the original quartic problem using a novel alternative optimization mechanism to linearize the quartic problem by introducing a linear regression model. Additionally, we find that gradually learning each batch of binary codes in a sequential mode, i.e. batch by batch, is greatly beneficial to the convergence of binary code learning. Based on this significant discovery and the proposed strategy, we introduce a scalable symmetric discrete hashing algorithm that gradually and smoothly updates each batch of binary codes. To further improve the smoothness, we also propose a greedy symmetric discrete hashing algorithm to update each bit of batch binary codes. Moreover, we extend the proposed optimization mechanism to solve the non-convex optimization problems for binary code learning in many other pairwise based hashing algorithms. Extensive experiments on benchmark single-label and multi-label databases demonstrate the superior performance of the proposed mechanism over recent state-of-the-art methods on two kinds of retrieval tasks: similarity and ranking order. The source codes are available on https://github.com/xsshi2015/Scalable-Pairwise-based-Discrete-Hashing.
@article{shi2021scalable, author = {Shi, Xiaoshuang and Xing, Fuyong and Zhang, Zizhao and Sapkota, Manish and Guo, Zhenhua and Yang, Lin}, journal = {IEEE Transactions on Image Processing}, note = {中科院JCR一区}, pages = {1130--1142}, title = {A Scalable Optimization Mechanism for Pairwise based Discrete Hashing}, volume = {30}, year = {2021}, }
2020
- IJCV
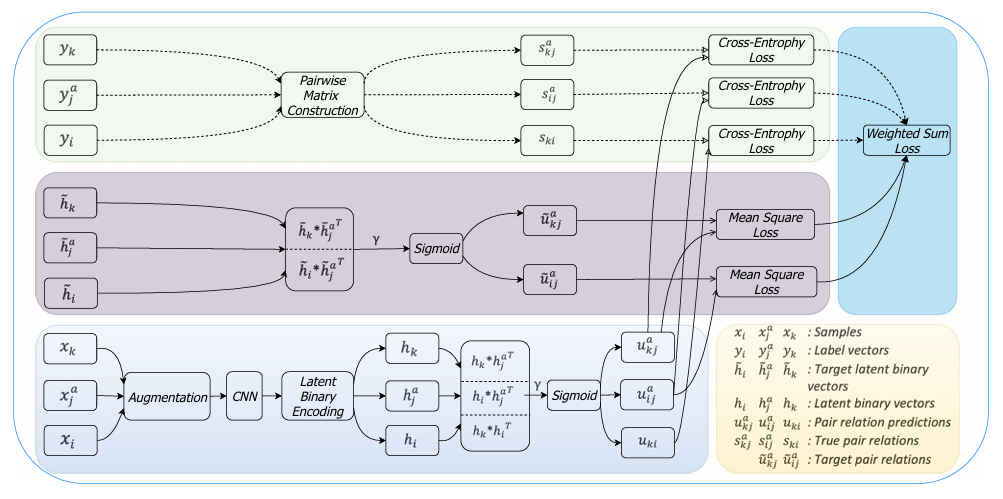 Anchor-Based Self-Ensembling for Semi-Supervised Deep Pairwise HashingXiaoshuang Shi, Zhenhua Guo, Fuyong Xing, and 2 more authorsInternational Journal of Computer Vision, 2020CCF-A
Anchor-Based Self-Ensembling for Semi-Supervised Deep Pairwise HashingXiaoshuang Shi, Zhenhua Guo, Fuyong Xing, and 2 more authorsInternational Journal of Computer Vision, 2020CCF-ADeep hashing has attracted considerable attention to tackle large-scale retrieval tasks, because of automatic and powerful feature extraction of convolutional neural networks and the gain of hashing in computation and storage costs. Most current supervised deep hashing methods only utilize the semantic information of labeled data without exploiting unlabeled data. However, data annotation is expensive and thus only scarce labeled data are available, which are difficult to represent the true distribution of all data. In this paper, we propose a novel semi-supervised deep pairwise hashing method to leverage both labeled and unlabeled data to learn hash functions. Our method utilizes the transduction of anchors to preserve the pairwise similarity relationship among both labeled and unlabeled samples. Additionally, to explore the semantic similarity information hidden in unlabeled data, it adopts self-ensembling to create strong ensemble targets for latent binary vectors of training samples and form a consensus predicting similarity relationship to multiple anchors. Unlike previous pairwise based hashing methods without maintaining the relevance among similar neighbors, we further explain and exhibit the capability of our method on preserving their relevance through calculating their similarities to anchors. Finally, extensive experiments on benchmark databases demonstrate the superior performance of the proposed method over recent state-of-the-art hashing methods on multiple retrieval tasks. The source codes of the proposed method are available on: https://github.com/xsshi2015/Semi-supervised-Deep-Pairwise-Hashing .
@article{shi2020anchor, author = {Shi, Xiaoshuang and Guo, Zhenhua and Xing, Fuyong and Liang, Yu and Yang, Lin}, journal = {International Journal of Computer Vision}, note = {CCF-A}, pages = {1-18}, title = {Anchor-Based Self-Ensembling for Semi-Supervised Deep Pairwise Hashing}, year = {2020}, } - MIA
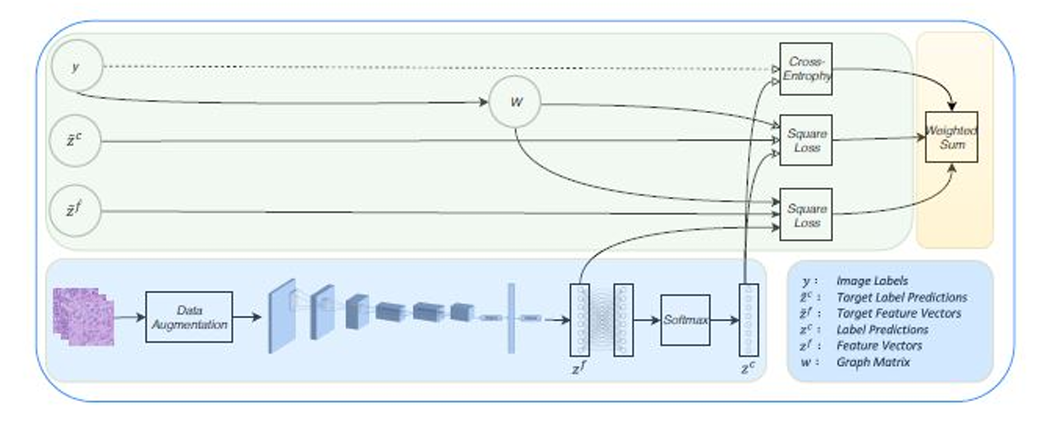 Graph temporal ensembling based semi-supervised convolutional neural network with noisy labels for histopathology image analysisXiaoshuang Shi, Hai Su, Fuyong Xing, and 3 more authorsMedical Image Analysis, 2020中科院JCR一区
Graph temporal ensembling based semi-supervised convolutional neural network with noisy labels for histopathology image analysisXiaoshuang Shi, Hai Su, Fuyong Xing, and 3 more authorsMedical Image Analysis, 2020中科院JCR一区Although convolutional neural networks have achieved tremendous success on histopathology image classification, they usually require large-scale clean annotated data and are sensitive to noisy labels. Unfortunately, labeling large-scale images is laborious, expensive and lowly reliable for pathologists. To address these problems, in this paper, we propose a novel self-ensembling based deep architecture to leverage the semantic information of annotated images and explore the information hidden in unlabeled data, and meanwhile being robust to noisy labels. Specifically, the proposed architecture first creates ensemble targets for feature and label predictions of training samples, by using exponential moving average (EMA) to aggregate feature and label predictions within multiple previous training epochs. Then, the ensemble targets within the same class are mapped into a cluster so that they are further enhanced. Next, a consistency cost is utilized to form consensus predictions under different configurations. Finally, we validate the proposed method with extensive experiments on lung and breast cancer datasets that contain thousands of images. It can achieve 90.5% and 89.5% image classification accuracy using only 20% labeled patients on the two datasets, respectively. This performance is comparable to that of the baseline method with all labeled patients. Experiments also demonstrate its robustness to small percentage of noisy labels.
@article{shi2020graph, author = {Shi, Xiaoshuang and Su, Hai and Xing, Fuyong and Liang, Yun and Qu, Gang and Yang, Lin}, journal = {Medical Image Analysis}, note = {中科院JCR一区}, pages = {101624}, title = {Graph temporal ensembling based semi-supervised convolutional neural network with noisy labels for histopathology image analysis}, volume = {60}, year = {2020}, } - AAAI
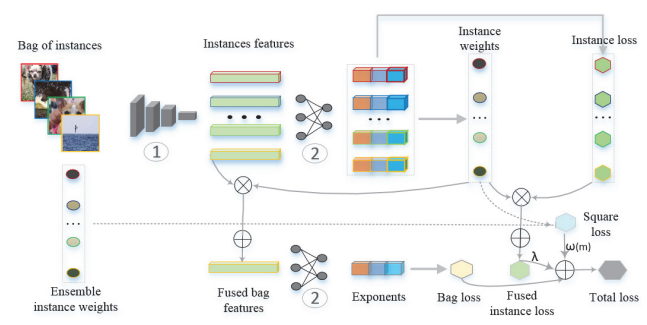 Loss-based attention for deep multiple instance learningXiaoshuang Shi, Fuyong Xing, Yuanpu Xie, and 3 more authorsIn AAAI Conference on Artificial Intelligence, 2020Spotlight, 20% acceptance rate, CCF-A
Loss-based attention for deep multiple instance learningXiaoshuang Shi, Fuyong Xing, Yuanpu Xie, and 3 more authorsIn AAAI Conference on Artificial Intelligence, 2020Spotlight, 20% acceptance rate, CCF-AAlthough attention mechanisms have been widely used in deep learning for many tasks, they are rarely utilized to solve multiple instance learning (MIL) problems, where only a general category label is given for multiple instances contained in one bag. Additionally, previous deep MIL methods firstly utilize the attention mechanism to learn instance weights and then employ a fully connected layer to predict the bag label, so that the bag prediction is largely determined by the effectiveness of learned instance weights. To alleviate this issue, in this paper, we propose a novel loss based attention mechanism, which simultaneously learns instance weights and predictions, and bag predictions for deep multiple instance learning. Specifically, it calculates instance weights based on the loss function, e.g. softmax+cross-entropy, and shares the parameters with the fully connected layer, which is to predict instance and bag predictions. Additionally, a regularization term consisting of learned weights and cross-entropy functions is utilized to boost the recall of instances, and a consistency cost is used to smooth the training process of neural networks for boosting the model generalization performance. Extensive experiments on multiple types of benchmark databases demonstrate that the proposed attention mechanism is a general, effective and efficient framework, which can achieve superior bag and image classification performance over other state-of-the-art MIL methods, with obtaining higher instance precision and recall than previous attention mechanisms. Source codes are available on https://github.com/xsshi2015/Loss-Attention.
@inproceedings{shi2020loss, author = {Shi, Xiaoshuang and Xing, Fuyong and Xie, Yuanpu and Zhang, Zizhao and Cui, Lei and Yang, Lin}, booktitle = {AAAI Conference on Artificial Intelligence}, note = {Spotlight, ~20\% acceptance rate, CCF-A}, title = {Loss-based attention for deep multiple instance learning}, year = {2020} }
2018
- PR
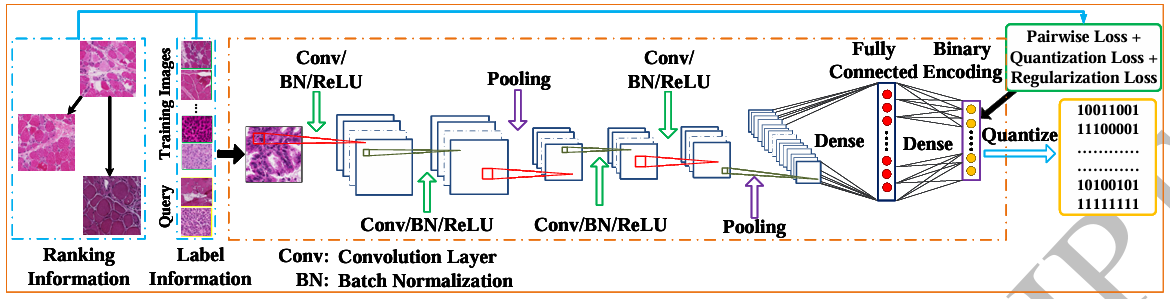 Pairwise based deep ranking hashing for histopathology image classification and retrievalXiaoshuang Shi, Manish Sapkota, Fuyong Xing, and 3 more authorsPattern Recognition, 2018中科院JCR一区
Pairwise based deep ranking hashing for histopathology image classification and retrievalXiaoshuang Shi, Manish Sapkota, Fuyong Xing, and 3 more authorsPattern Recognition, 2018中科院JCR一区Hashing has become a popular tool on histopathology image analysis due to the significant gain in both computation and storage. However, most of current hashing techniques learn features and binary codes individually from whole images, or emphasize the inter-class difference but neglect the relevance order within the same classes. To alleviate these issues, in this paper, we propose a novel pairwise based deep ranking hashing framework. We first define a pairwise matrix to preserve intra-class relevance and inter class difference. Then we propose an objective function that utilizes two identical continuous matrices generated by the hyperbolic tangent (tanh) function to approximate the pairwise matrix. Finally, we incorporate the objective function into a deep learning architecture to learn features and binary codes simultaneously. The proposed framework is validated on 5,356 skeletal muscle and 2,176 lung cancer images with four types of diseases, and it can achieve 97.49% classification accuracy, 97.49% mean average precision (MAP) with 100 returned images, and 0.51 NDCG score with 50 retrieved neighbors on 2,032 query images.
@article{shi2018pairwise, author = {Shi, Xiaoshuang and Sapkota, Manish and Xing, Fuyong and Liu, Fujun and Cui, Lei and Yang, Lin}, journal = {Pattern Recognition}, note = {中科院JCR一区}, pages = {14--22}, title = {Pairwise based deep ranking hashing for histopathology image classification and retrieval}, volume = {81}, year = {2018}, } - PR
 Self-learning for face clusteringXiaoshuang Shi, Zhenhua Guo, Fuyong Xing, and 2 more authorsPattern Recognition, 2018中科院JCR一区
Self-learning for face clusteringXiaoshuang Shi, Zhenhua Guo, Fuyong Xing, and 2 more authorsPattern Recognition, 2018中科院JCR一区A self-learning framework including image decorrelation and a self-paced learning process, for face clustering.•Providing quantitative analysis on the Gaussian distribution of global and local whitening faces.•A novel self-paced learning model for face clustering, inspired by the learning process of human.
@article{shi2018self, author = {Shi, Xiaoshuang and Guo, Zhenhua and Xing, Fuyong and Cai, Jinzheng and Yang, Lin}, journal = {Pattern Recognition}, note = {中科院JCR一区}, pages = {279--289}, title = {Self-learning for face clustering}, volume = {79}, year = {2018}, }
2017
- AAAI
 Asymmetric discrete graph hashingXiaoshuang Shi, Fuyong Xing, Kaidu Xu, and 2 more authorsIn AAAI Conference on Artificial Intelligence, 2017Spotlight, 25% acceptance rate, CCF-A
Asymmetric discrete graph hashingXiaoshuang Shi, Fuyong Xing, Kaidu Xu, and 2 more authorsIn AAAI Conference on Artificial Intelligence, 2017Spotlight, 25% acceptance rate, CCF-ARecently, many graph based hashing methods have been emerged to tackle large-scale problems. However, there exists two major bottlenecks: (1) directly learning discrete hashing codes is an NP-hardoptimization problem; (2) the complexity of both storage and computational time to build a graph with n data points is O(n2). To address these two problems, in this paper, we propose a novel yetsimple supervised graph based hashing method, asymmetric discrete graph hashing, by preserving the asymmetric discrete constraint and building an asymmetric affinity matrix to learn compact binary codes.Specifically, we utilize two different instead of identical discrete matrices to better preserve the similarity of the graph with short binary codes. We generate the asymmetric affinity matrix using m (m << n) selected anchors to approximate the similarity among all training data so that computational time and storage requirement can be significantly improved. In addition, the proposed method jointly learns discrete binary codes and a low-dimensional projection matrix to further improve the retrieval accuracy. Extensive experiments on three benchmark large-scale databases demonstrate its superior performance over the recent state of the arts with lower training time costs.
@inproceedings{shi2017asymmetric, author = {Shi, Xiaoshuang and Xing, Fuyong and Xu, Kaidu and Sapkota, Manish and Yang, Lin}, booktitle = {AAAI Conference on Artificial Intelligence}, note = {Spotlight, ~25\% acceptance rate, CCF-A}, pages = {2541--2547}, title = {Asymmetric discrete graph hashing}, year = {2017}, } - MICCAI
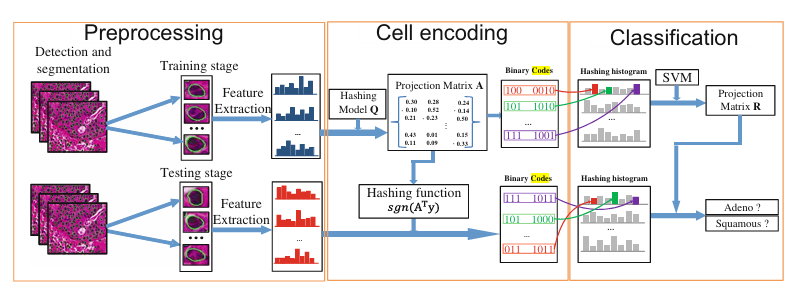 Cell encoding for histopathology image classificationXiaoshuang Shi, Fuyong Xing, Yuanpu Xie, and 1 more authorIn International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), 201732% acceptance rate, CCF-B
Cell encoding for histopathology image classificationXiaoshuang Shi, Fuyong Xing, Yuanpu Xie, and 1 more authorIn International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), 201732% acceptance rate, CCF-BAlthough many image analysis algorithms can achieve good performance with sufficient number of labeled images, manually labeling images by pathologists is time consuming and expensive. Meanwhile, with the development of cell detection and segmentation techniques, it is possible to classify pathology images by using cell-level information, which is crucial to grade different diseases; however, it is still very challenging to efficiently conduct cell analysis on large-scale image databases since one image often contains a large number of cells. To address these issues, in this paper, we present a novel cell-based framework that requires only a few labeled images to classify large-scale pathology ones. Specifically, we encode each cell into a set of binary codes to generate image representation using a semi-supervised hashing model, which can take advantage of both labeled and unlabeled cells. Thereafter, we map all the binary codes in one whole image into a single histogram vector and then learn a support vector machine for image classification. The proposed framework is validated on one large-scale lung cancer image dataset with two types of diseases, and it can achieve 87.88% classification accuracy on 800 test images using only 5 labeled images of each disease.
@inproceedings{shi2017cell, author = {Shi, Xiaoshuang and Xing, Fuyong and Xie, Yuanpu and Yang, Lin}, booktitle = {International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI)}, note = {~32\% acceptance rate, CCF-B}, pages = {30--38}, title = {Cell encoding for histopathology image classification}, year = {2017}, } - MIA
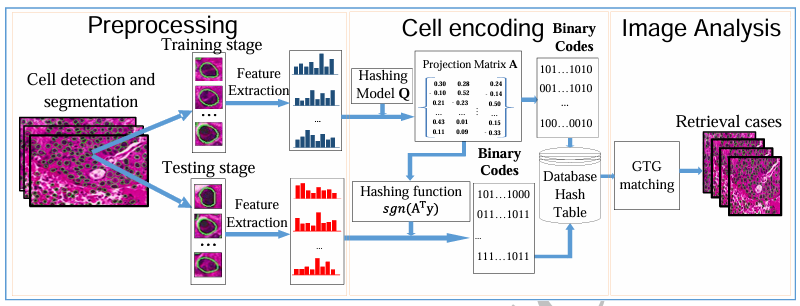 Supervised graph hashing for histopathology image retrieval and classificationXiaoshuang Shi, Fuyong Xing, Kaidi Xu, and 3 more authorsMedical Image Analysis, 2017中科院JCR一区
Supervised graph hashing for histopathology image retrieval and classificationXiaoshuang Shi, Fuyong Xing, Kaidi Xu, and 3 more authorsMedical Image Analysis, 2017中科院JCR一区In pathology image analysis, morphological characteristics of cells are critical to grade many diseases. With the development of cell detection and segmentation techniques, it is possible to extract cell-level information for further analysis in pathology images. However, it is challenging to conduct efficient analysis of cell-level information on a large-scale image dataset because each image usually contains hundreds or thousands of cells. In this paper, we propose a novel image retrieval based framework for large-scale pathology image analysis. For each image, we encode each cell into binary codes to generate image representation using a novel graph based hashing model and then conduct image retrieval by applying a group-to-group matching method to similarity measurement. In order to improve both computational efficiency and memory requirement, we further introduce matrix factorization into the hashing model for scalable image retrieval. The proposed framework is extensively validated with thousands of lung cancer images, and it achieves 97.98% classification accuracy and 97.50% retrieval precision with all cells of each query image used.
@article{shi2017supervised, author = {Shi, Xiaoshuang and Xing, Fuyong and Xu, Kaidi and Xie, Yuanpu and Su, Hai and Yang, Lin}, journal = {Medical Image Analysis}, note = {中科院JCR一区}, pages = {117--128}, title = {Supervised graph hashing for histopathology image retrieval and classification}, volume = {42}, year = {2017}, }
2016
- ECCV
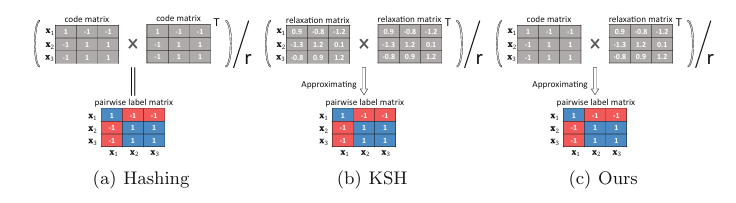 Kernel-based supervised discrete hashing for image retrievalXiaoshuang Shi, Fuyong Xing, Jinzheng Cai, and 3 more authorsIn European Conference on Computer Vision (ECCV), 201626% acceptance rate, CCF-B
Kernel-based supervised discrete hashing for image retrievalXiaoshuang Shi, Fuyong Xing, Jinzheng Cai, and 3 more authorsIn European Conference on Computer Vision (ECCV), 201626% acceptance rate, CCF-BRecently hashing has become an important tool to tackle the problem of large-scale nearest neighbor searching in computer vision. However, learning discrete hashing codes is a very challenging task due to the NP hard optimization problem. In this paper, we propose a novel yet simple kernel-based supervised discrete hashing method via an asymmetric relaxation strategy. Specifically, we present an optimization model with preserving the hashing function and the relaxed linear function simultaneously to reduce the accumulated quantization error between hashing and linear functions. Furthermore, we improve the hashing model by relaxing the hashing function into a general binary code matrix and introducing an additional regularization term. Then we solve these two optimization models via an alternative strategy, which can effectively and stably preserve the similarity of neighbors in a low-dimensional Hamming space. The proposed hashing method can produce informative short binary codes that require less storage volume and lower optimization time cost. Extensive experiments on multiple benchmark databases demonstrate the effectiveness of the proposed hashing method with short binary codes and its superior performance over the state of the arts.
@inproceedings{shi2016kernel, author = {Shi, Xiaoshuang and Xing, Fuyong and Cai, Jinzheng and Zhang, Zizhao and Xie, Yuanpu and Yang, Lin}, booktitle = {European Conference on Computer Vision (ECCV)}, note = {~26\% acceptance rate, CCF-B}, pages = {419--433}, title = {Kernel-based supervised discrete hashing for image retrieval}, year = {2016}, } - TPAMI
 Two-Dimensional Whitening Reconstruction for Enhancing Robustness of Principal Component AnalysisXiaoshuang Shi, Zhenhua Guo, Feiping Nie, and 3 more authorsIEEE Transactions on Pattern Analysis and Machine Intelligence, 2016中科院JCR一区
Two-Dimensional Whitening Reconstruction for Enhancing Robustness of Principal Component AnalysisXiaoshuang Shi, Zhenhua Guo, Feiping Nie, and 3 more authorsIEEE Transactions on Pattern Analysis and Machine Intelligence, 2016中科院JCR一区Principal component analysis (PCA) is widely applied in various areas, one of the typical applications is in face. Many versions of PCA have been developed for face recognition. However, most of these approaches are sensitive to grossly corrupted entries in a 2D matrix representing a face image. In this paper, we try to reduce the influence of grosses like variations in lighting, facial expressions and occlusions to improve the robustness of PCA. In order to achieve this goal, we present a simple but effective unsupervised preprocessing method, two-dimensional whitening reconstruction (TWR), which includes two stages: 1) A whitening process on a 2D face image matrix rather than a concatenated 1D vector; 2) 2D face image matrix reconstruction. TWR reduces the pixel redundancy of the internal image, meanwhile maintains important intrinsic features. In this way, negative effects introduced by gross-like variations are greatly reduced. Furthermore, the face image with TWR preprocessing could be approximate to a Gaussian signal, on which PCA is more effective. Experiments on benchmark face databases demonstrate that the proposed method could significantly improve the robustness of PCA methods on classification and clustering, especially for the faces with severe illumination changes.
@article{shi2016two, author = {Shi, Xiaoshuang and Guo, Zhenhua and Nie, Feiping and Yang, Lin and You, Jane and Tao, Dacheng}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence}, note = {中科院JCR一区}, number = {10}, pages = {2130--2136}, title = {Two-Dimensional Whitening Reconstruction for Enhancing Robustness of Principal Component Analysis}, volume = {38}, year = {2016}, }
2015
- TIP
 A Framework of Joint Graph Embedding and Sparse Regression for Dimensionality ReductionXiaoshuang Shi, Zhenhua Guo, Zhihui Lai, and 3 more authorsIEEE Transactions on Image Processing, 2015中科院JCR一区
A Framework of Joint Graph Embedding and Sparse Regression for Dimensionality ReductionXiaoshuang Shi, Zhenhua Guo, Zhihui Lai, and 3 more authorsIEEE Transactions on Image Processing, 2015中科院JCR一区Over the past few decades, a large number of algorithms have been developed for dimensionality reduction. Despite the different motivations of these algorithms, they can be interpreted by a common framework known as graph embedding. In order to explore the significant features of data, some sparse regression algorithms have been proposed based on graph embedding. However, the problem is that these algorithms include two separate steps: 1) embedding learning and 2) sparse regression. Thus their performance is largely determined by the effectiveness of the constructed graph. In this paper, we present a framework by combining the objective functions of graph embedding and sparse regression so that embedding learning and sparse regression can be jointly implemented and optimized, instead of simply using the graph spectral for sparse regression. By the proposed framework, supervised, semisupervised, and unsupervised learning algorithms could be unified. Furthermore, we analyze two situations of the optimization problem for the proposed framework. By adopting an L-2,L-1-norm regularization for the proposed framework, it can perform feature selection and subspace learning simultaneously. Experiments on seven standard databases demonstrate that joint graph embedding and sparse regression method can significantly improve the recognition performance and consistently outperform the sparse regression method.
@article{shi2015framework, author = {Shi, Xiaoshuang and Guo, Zhenhua and Lai, Zhihui and Yang, Yujiu and Bao, Zhifeng and Zhang, David}, journal = {IEEE Transactions on Image Processing}, note = {中科院JCR一区}, number = {4}, pages = {1341--1355}, title = {A Framework of Joint Graph Embedding and Sparse Regression for Dimensionality Reduction}, volume = {24}, year = {2015}, }
2014
- PR
 Face recognition by sparse discriminant analysis via joint L2,1-norm minimizationXiaoshuang Shi, Yujiu Yang, Zhenhua Guo, and 1 more authorPattern Recognition, 2014中科院JCR一区
Face recognition by sparse discriminant analysis via joint L2,1-norm minimizationXiaoshuang Shi, Yujiu Yang, Zhenhua Guo, and 1 more authorPattern Recognition, 2014中科院JCR一区Recently, joint feature selection and subspace learning, which can perform feature selection and subspace learning simultaneously, is proposed and has encouraging ability on face recognition. In the literature, a framework of utilizing L2,1-norm penalty term has also been presented, but some important algorithms cannot be covered, such as Fisher Linear Discriminant Analysis and Sparse Discriminant Analysis. Therefore, in this paper, we add L2,1-norm penalty term on FLDA and propose a feasible solution by transforming its nonlinear model into linear regression type. In addition, we modify the optimization model of SDA by replacing elastic net with L2,1-norm penalty term and present its optimization method. Experiments on three standard face databases illustrate FLDA and SDA via L2,1-norm penalty term can significantly improve their recognition performance, and obtain inspiring results with low computation cost and for low-dimension feature.
@article{shi2014face, author = {Shi, Xiaoshuang and Yang, Yujiu and Guo, Zhenhua and Lai, Zhihui}, journal = {Pattern Recognition}, note = {中科院JCR一区}, number = {7}, pages = {2447--2453}, title = {Face recognition by sparse discriminant analysis via joint L2,1-norm minimization}, volume = {47}, year = {2014}, }